查询状态
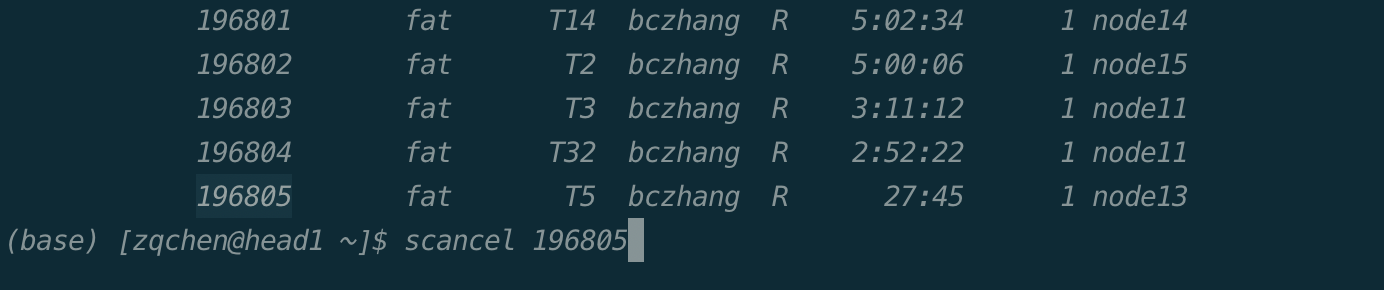
sinfo:查看节点与分区状态
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
normal* up infinite 10 idle node[1-10]
fat up infinite 3 mix node[11-13]
fat up infinite 2 alloc node[14-15]
关键词 |
含义 |
|
分区名,对节点的逻辑分组。不同的分区会设置不同权限、资源限制等。 |
|
可用状态: |
|
该分区的作业最大运行时长限制, |
|
节点数量 |
|
状态: |
|
节点列表 |
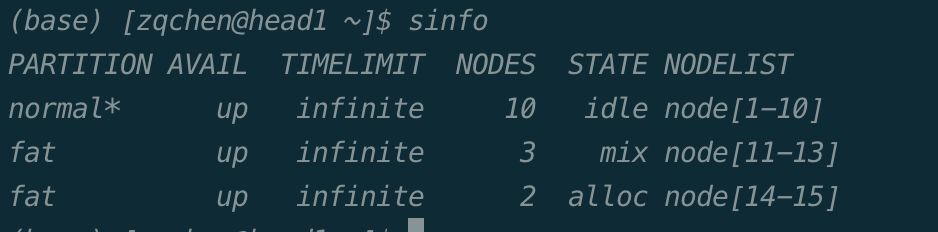
squeue:查看队列状态
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
8628 cpu vasp_cpu yangx17 PD 0:00 2 (QOSMaxNodePerUserLimit)
8629 cpu vasp_cpu yangx17 PD 0:00 2 (QOSMaxNodePerUserLimit)
8630 cpu vasp_cpu yangx17 PD 0:00 2 (QOSMaxNodePerUserLimit)
8636 cpu vasp_cpu mab2019 PD 0:00 4 (Resources)
8637 cpu vasp lizhenhu PD 0:00 1 (Priority)
5042 cpu HICE_WAC xum17 R 16-22:28:14 4 n[114-117]
5044 cpu LICE_WAC xum17 R 16-22:21:58 4 n[29,41-43]
5519 cpu c zhaosy16 R 14-22:00:21 5 n[93-95,165-166]
5783 cpu c liangt20 R 13-20:54:50 5 n[30-32,156-157]
关键词 |
含义 |
|
作业的id号,每个成功提交的任务都会有唯一的id |
|
分区名 |
|
作业名称,默认为提交脚本的名称 |
|
用户名,提交该作业的用户名 |
|
作业状态: |
|
作业运行时间 |
|
作业占节点数 |
|
作业所占节点列表,如果是排队状态的任务,则会给出排队原因 |
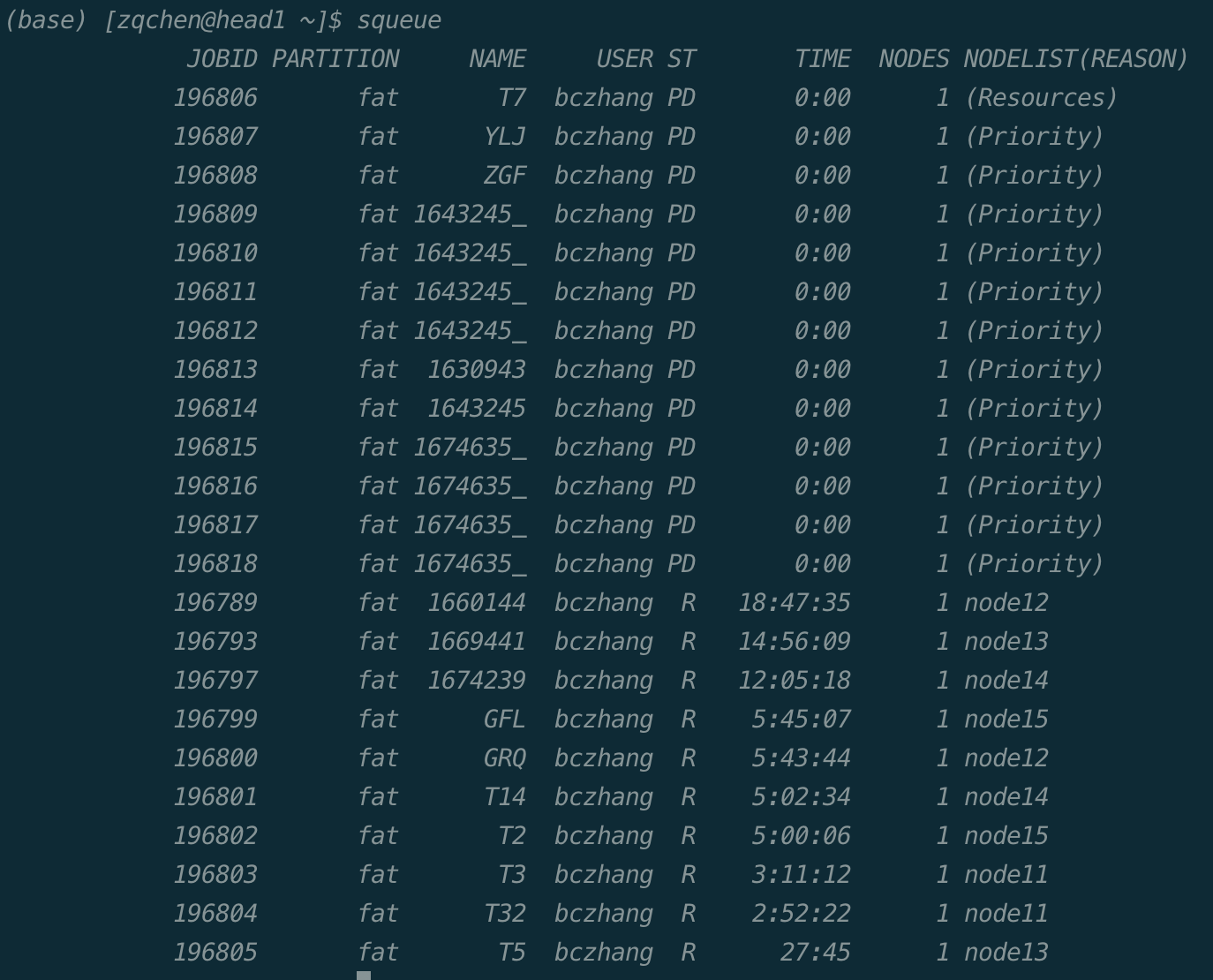
scancel:取消作业